2. h5gate format specification language¶
| Revision: | 0.9.1 |
|---|---|
| Date: | May 1, 2017 [1] |
2.1. Introduction¶
This API for the NWB format is built using a domain-independent specification language which allows specifying formats for data stored in HDF5. The system provides the following features:
- A single, human-readable file is used to specify a “core” format.
(For the NWB format, this file is
nwb_core.py). - The core format can be extended to incorporate new use cases by creating “extensions” to the core format.
- Both the core format and extensions are written in the same specification language (described in this document).
- Write APIs are provided for both Python and Matlab. The write APIs are independent of the format and do not change when extensions are used. This allows extensions to be shared without the API software needing to be modified to use different extensions.
- Files in the fomat can be validated to ensure that they are consistent with the core format and any used extensions.
- Documentation for the core format and extensions can be generated from the specification files (and from data files created using the API because these include the specifications files).
- Specification files (both for the core format and extensions) can be validated using JSON Schema (http://json-schema.org).
The main program that implements these features is called “h5gate.” The “h5” refers to HDF5 (but other backends may be possible). The “gate” refers to the concept of controlling access, like a gate in a fence, because the write APIs control the addition of data into files to conform to that indicated by the format specification. The specification language and h5gate were designed for the NWB format, but may also be useful for other formats. The operation of the specification language is shown in Fig. 2.1.1.
| [1] | The reversion number is for this document and is independent of the version number for the NWB format. The date is the last modification date of this document. |
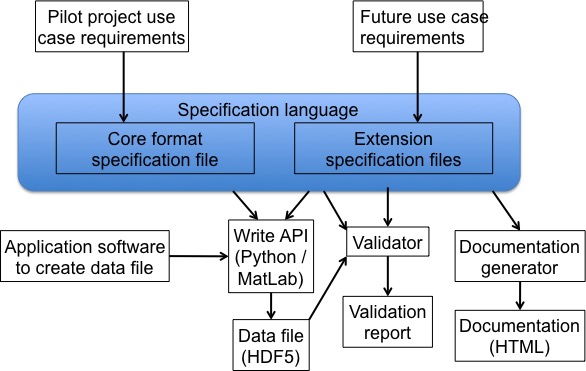
Fig. 2.1.1 How the specification language is used.
2.2. High-level organization¶
The specification language is written using a Python dictionary in a JSON-like syntax, which can easily be converted to JSON. A Python dictionary is used rather than pure JSON because Python allows inserting comments and also provides more readable ways to include long strings.
2.2.1. Schema-Id (or namespace)¶
The top-level of a format specification has the following form:
{"fs": {
"ns1": <specification for schema 'ns1'>,
"ns2": *\<specification for schema 'ns2'>,
"ns3": *\<specification for schema 'ns3'>, ... }
}
The top level identifier must be “fs”. (This stands for “format specification”). The value of “fs” is a dictionary with each key the “schema-Id” (or “namespace”) of a format specification that is associated with that schema-Id. The schema-Ids can be any valid Python string (they are not restricted to start with ‘ns’). One of the schemas-Ids is designated as the “default” and it is associated with the core format. Other schema-Ids are associated with extensions to the core format. Information indicating where to obtain the specifications (usually names of files containing the specifications) and the default schema-Id are passed into the API software when it is initialized.
2.2.2. Top level components¶
The specification associated with each schema-Id is a Python dictionary with three keys: info, schema, and doc. e.g.:
{
"info": <info specification>,
"schema": <schema specification>,
"doc": <auxiliary documentation>,
}
“info” and “schema” are required. “doc” is optional. <info
specification> has the following form:
{
"name": "<Name of specification>",
"version": "<version number>",
"date": "<date last modified or released>",
"author": "<author name>",
"contact": "<author email or other contact info>",
"description": "<description of the specification>"
}
The <schema specification> section defines the groups, datasets and
relationship that make up the format. This is the main part of the
format specification. It is described in the following sections.
The <auxiliary documentation> section is for text that is added to
documentation that is generated from the format
specification, using the make_docs.py tool. This is not described
further in this document, but the structure and operation can be deduced
by examining this part of the NWB format specification in file
nwb_core.py and the generated documentation for the NWB format.
The top level components are 2.2.2 Top level components (see above). They are also at 2.2.2 Top level components (Top level components) (also see above).
But these work: Top level components (see above). They are also at top_level_components (also see above).
2.2.3. Schema specification¶
The <schema specification> consist of a Python dictionary where each key
has the following form:
[<absolute_path>] <identifier> [<group-flag>] [<quantity-flag>]
<absolute_path> is optional. If present, it starts with a slash (“/”),
and specifies the absolute location within an HDF5 file of the group or
dataset. For the root group, the absolute path is empty and the
identifier is “/”.
<identifier> is required. Identifiers that start with “<“ and end
with “>” have a “variable” name, that is, the name is specified
through an API call when creating the group or dataset. If the identifier
does not start and end with angle brackets, then the name is fixed and is
the same as the identifier.
<group-flag> is optional. If present, it is a “/” to indicate that the
identifier is associated with a group. If absent, the identifier is associated
with a dataset.
<quantity_flag> is optional. It is used to indicate if the HDF5 dataset
or group associated with the identifier is required, optional, recommended or
if there are multiple instances required. (The term “quantity” was chosen
for this because some of the characters used for the <quantity_flag> have
the same meaning as characters used to specifies quantities in regular
expressions). If present, the <quantity_flag> is a single character,
one of: “?”, “!”, “^”, “+” or “*”. These mean:
! - Required (this is the default)
? - Optional
^ - Recommended
+ - One or more instances of variable-named identifier required
* - Zero or more instances of variable-named identifier allowed
Some example schema specification keys and their meaning are given below:
Unspecified location (no leading slash):
foo - dataset, name is “foo”
foo/ - group, name is “foo”
<foo> - dataset, variable name
<foo>/ - group, variable name
Specified location (has leading slash). Meaning same as above, but location specified:
/some/path/foo – dataset, name is “foo”, located at /some/path/
/some/path/foo/ – group, name is “foo”, located at /some/path/
/some/path/<foo> – dataset, variable name, located at /some/path
/some/path/<foo>/ – group, variable name, located at /some/path
With quantity specified:
foo? – dataset, name is “foo”. Is optional
foo/^ – group, name is “foo”. Is recommended
<foo>* – dataset, variable name, zero or more allowed
<foo>+ – group, variable name, at least one required
When an absolute path is specified (or if the identifier is for the root group) the identifier is “anchored” to the specified location. If there is no absolute path, then the group or dataset associated with the identifier can be incorporated into other groups using the “include” or “merge” directives that are described below.
2.2.4. Extensions¶
As mentioned, extensions to the core format are specified using schema-Ids that are different from the schema-id used for the core format. The way that extensions are implemented is very simple: The schema specified in extensions are simply “merged” into the schema specified in the core format based on having the same absolute path (if given) and the same identifier. For example, if the core format schema includes key “<foo>/” (specifying a group with a variable name “foo”) and an extension also includes a key “<foo>/”, the value associated with both of these (which must be a dictionary) are combined to form the combined specification of the core format and the extension. While it’s possible to define multiple extensions in the same file (as illustrated in Section 2.2.1 Schema-Id (or namespace)) normally, the specification associated with each schema-Id will be in a separate file as illustrated below:
File containing specification for core format:
{"fs": {
"core": <specification for core format>
}}
File containing specification for extension ex1:
{"fs": {
"ex1": <specification for extension ex1>
}}
File containing specification for extension ex2:
{"fs": {
"ex2": <specification for extension ex2>
}}
2.3. Specification of groups¶
2.3.1. Overall form¶
The specification of a group (i.e. value of a schema specification identifier that is followed by a slash) is a Python dictionary with the following form:
{
"description": "<description of group>",
"_description": "<description in case there is a dataset named 'description'>",
"_required": <required specification>,
"_exclude_in": <exclude_in specification>,
"_properties": <properties specification>",
"attributes": <attributes specification>,
"merge": <list of groups to merge>,
"merge+": <list of group (base class) to merge>,
"include": <dictionary of structures to include>,
"link": <link specification>,
"dataset_id[<qty-flag>]": { <dataset specification> },
"group_id/[<qty-flag>]": { <group specification> }
}
None of the key-value pairs are required. All but the last two are
described in the Section 2.3.2 Group specification keys below. The last two
(“dataset_id”, and “group_id/”) are used to specify a group or dataset
inside the group. The specification for these is the same as the
specification for top-level groups (described in this section) and for
top-level datasets (describe in :numref”:specification_of_datasets).
There can be any number of groups or datasets specified inside a group.
The optional <qty-flag> after “dataset_id” and “group_id/” is the same
as the <quantity-flag> described in Section 2.2.3 Schema specification.
2.3.2. Group specification keys¶
2.3.2.1. “description”¶
The value of the group specification “description” key is a string describing the group.
2.3.2.2. “_description”¶
The key “_description” (has an underscore in front) is used in place of “description” in case the key “description” is used to specify a dataset in the group named “description”. (In this case the value of the “description” key would be a JSON Object (Python dictionary) instead of a string.)
2.3.2.3. “_required”¶
The <required specification> is a dictionary with each key an
identifier associated with some condition, and each value a list of
tuples. First element of each tuple is a string (called the “condition
string”) that contains a logical expression that has variables matching
members of the group. The condition string specifies which combinations
of group members are required. The second element of each tuple is an
error message that is displayed if the requirements of the condition
string are not met. An example required specification is shown below:
{ "start_time" :
["starting_time XOR timestamps",
"starting_time or timestamps must be present, but not both."],
"control":
["(control AND control_description) OR (NOT control AND NOT control_description)",
"If control or control_description are present, then both must be present.")]}
The logical expression can contain the following logical operators:
{"AND": 'and', 'XOR': '^', 'OR': 'or', 'NOT': 'not'}
either the upper-case strings (keys in the above JSON object) or the corresponding Python operator (values associated with the above keys) can be used.
2.3.2.4. “exclude_in”¶
The exclude_in specification is used to specify locations in the HDF5 file under which particular members of this group should not be present (or be optional). It has the form:
{ "/path1": ["id1", "id2", "id3", ...],
"/path2": [<ids for path2>], ... }
Each id is the identifier of a member group or dataset. The id in the list can be followed by characters ”!”, “^”, ”?” to respectively indicate that the id must not be present, should not be present or is optional under the specified path. If the last character is not “!”, “^” or “?” then “!” is assumed. An example is:
"_exclude\_in": {
"/stimulus/templates":
[ "starting_time!", "timestamps!", "num_samples?"] }
2.3.2.5. “_properties”¶
The “_properties” specification is optional. If present, the value must be a dictionary containing any combination of the keys: “abstract”, “closed” and “create”. The value of included key(s) must be type boolean (True or False). Key “abstract” has value True to indicate that this group is “abstract” (cannot be created directly, but instead must be subclassed via the “merge” directive). Key “closed” is True to indicate that additional members (groups and datasets beyond what are defined in the specification) are not allowed in this group. Key “create” is True to indicate that a write API should automatically create this group if the group is specified as being required and it is not created.
2.3.2.6. Group “attributes”¶
The value of the group specification “attributes” key is a Python dictionary of the following form:
{
"attr_name_1[<qty_flag>]": <specification for attr_name_1>,
"attr_name_2[<qty-flag>]": <specification for attr_name_2>,
... }
The keys are the attribute names, optionally followed by a <qty_flag>.”
The <qty_flag> (stands for ‘quantity flag’ is similar to that for
groups and data sets. It specifies if the attribute is required (“!”)–
the default, optional (“?”) or recommended (“^”). The value of each key
is the specification for that attribute. Each attribute specification
has the following form:
{
"data_type": <data_type>,
"dimensions": <dimensions list>,
"description": "<description of attribute>",
"value": <value to store>,
"const": <True or False>,
"autogen": <autogen specification>,
"references": <reference specification>,
"dim1": <dimension specification>,
"dim2": <dimension specification>
}
Only “data_type” is required. The value (<data_type>) is a string
specifying the data_type of the attribute. Allowable values include:
"float" – indicates a floating point number
"int" – indicates an integer
"uint" – unsigned integer
"number" – indicates either a floating point or an integer
"text" – a text string
For “float”, “int” and “uint”, a default size (in bits) can be specified by appending the size to the type, e.g., “int32”. If “!” is appended to the default size, e.g. “float64!”, then the default size is also the required minimum size.
If the attribute stores an array, the <dimensions list> specifies
the list of dimensions. The format for this is the same as the
<dimensions list> for datasets which is described in Section
2.4.1.3 Dataset dimensions. If no <dimension list> is given, the
attribute stores a scalar value.
The description is a text string describing the attribute.
The “value” key denotes the value to store in the attribute. If a value is specified and “const”:True is specified, then the value is treated as a constant and cannot be changed by the API.
The autogen specification is described in Section 2.5 Autogen.
The references specification and the <dimension specification>
are the same as that used for datasets. They are respectively described
in Sections 2.4.1.5 “references” and 2.4.2 dimension specification.
2.3.2.7. “merge”¶
The merge specification is used to merge the specification of other groups into the current group. It consists of a Python list of the groups (identifiers described in Section 2.2.3 Schema specification) to merge. (Each element of the list must have a trailing slash since they all must be groups).
2.3.2.8. “merge+”¶
The merge+ specification (“+” character after the word “merge”) is used to merge the specification of a single group (or subclass of it) into the current group. The group merged is either the group given in the list, or a subclass of that group (where subclasses are defined as a group that merges the specified group). In the API call to make the group, a subclass is specified by appending a dash then the subclass name after the identifier used to make the group. For example, in the NWB format, if the group name is “corrected” and the base class (in the “merge+” specification) is “<image-series>”, then the call to create a subclass (such as “<TwoPhotonSeries>”) would be:
make_group("corrected-<TwoPhotonSeries>")
2.3.2.9. “include”¶
The include specification is used to include the specification of a
group or dataset inside the current group. The format is a Python
dictionary (also JSON object), in which each key is the key associated
with a group or dataset to include and the values are a dictionary used
to specify properties and values that are merged into the included structure
and also options for the include. The key that designate the group or
dataset to include may have a final character that specifies a quantity
(same as described in Section 2.2.3 Schema specification). Options for
the include are specified by key \_options. Currently, there is only
one option: “subclasses” which has value True to indicate that “subclasses”
of the included group should also be included. Subclasses of a group are
groups that inherit from a base group using the “merge” directive
(described in the next section). Some examples of the include directive
are shown below:
# include with subclasses
"include": { "<TimeSeries>/*":{"\_options": {"subclasses": True}}}
# include without subclasses
"include": {"<TimeSeries>/*": {}}
2.3.2.10. “merge” vs. “include”¶
The merge operation implements a type of subclassing because properties of the merged in groups (the superclasses) are included, but overridden by properties in the group specifying the merge if there are conflicts. The include specification implements a type of reuse. The merge and include operations are illustrated by the following diagram:
| merge – (for subclassing) | include – for reuse |
|---|---|
“A/”: {
“x”: ...,
“y”: ...
}
“B/”: {
“merge”: [“A/”,],
“m”: ...,
“n”: ...,
}
Result:
“B/”: {
“x”: ...,
“y”: ...,
“m”: ...,
“n”: ...,
}
|
“A/”: {
“x”: ...,
“y”: ...
}
“B/”: {
“include”: {“A/”: {}},
“m”: ...,
“n”: ...,
}
Result:
“B/”: {
“m”: ...,
“n”: ...,
“A/”: {
“x”: ...,
“y”: ...
}
}
|
2.3.2.11. “link”¶
The link specification is used to indicate that the group must be HDF5 link to another group. (Hard or soft links can be used, but soft links are recommended). The link specification is a Python dictionary. It has the following form:
{
"target_type": "<target_type>",
"allow_subclasses": <True or False>,
}
<target_type> specifies the key for a group in the top level structure
of a namespace. It is used to indicate that the link must be to an
instance of that structure. “allow_subclasses” is set to True to
indicate the link can be to subclasses of the target structure.
Subclasses are structures that include the target using a “merge”
specification. Neither of the keys are required. The default value for
“allow_subclasses” is False. If <target_type> is not specified, then
the link can be to any group.
2.4. Specification of datasets¶
2.4.1. Overall form¶
The specification of a dataset (i.e. value associated with a schema specification key described in Section 2.2.3 Schema specification that does not have a trailing slash) is a Python dictionary with the following form:
{
"description": "<description>",
"data_type": <data_type>,
"dimensions": <dimensions list>, # required if dataset is not scalar
"attributes": <attributes specification>,
"references": "<reference target specification>",
"link": <link specification>,
"autogen": <autogen specification>,
"dim1": <dimension specification>,
"dim2": <dimension specification>,
...
}
Either the “data_type” or “link” property must be present. All others are optional. If the dataset is specified and is an array (not scalar) than the dimensions property is required. The autogen specification is described in Section 2.5 Autogen. Others are described below.
2.4.1.1. 4.2.1 dataset “description”¶
A string describing the dataset.
2.4.1.2. “data_type”¶
A string indicating the type of data stored. This is the same as the
<data_type for group attributes, described in Section 2.3.2.6 Group “attributes”.
2.4.1.3. Dataset dimensions¶
If present, <dimension_list> is either a list of named
dimensions, e.g.: [“dim1”, “dim2”, ...], or a list of lists of named
dimensions, e.g.: [[“dim1”], [“dim1”, “dim2”]]. The first form is
used if there is only one possibility for the number of dimensions. The
second form is used if there are multiple possible number of dimensions.
Each dimension name is a string (providing a dimension name). Dimensions
names are used both for specifying properties of dimensions (as described
in Section 2.4.2 dimension specification) and for specifying relationships
between datasets.
The special dimension name "*unlimited*" is used to indicate that the
number of elements stored in this dimension can increase (by appending to
the dataset) after the dataset is created. Other dimensions are fixed in
size once the dataset is created.
2.4.1.4. Dataset “attributes”¶
Dataset attributes are specified in the same was as group attributes, described in Section 2.3.2.6 Group “attributes”.
2.4.1.5. “references”¶
The references property is used to indicate that the values stored in the dataset are referencing groups, datasets or parts of other datasets in the file. The value of the references property is a reference target specification. This has one of the following four forms:
- <path_to_dataset>.dimension
- <path_to_dataset>.dimension.component
- <path_to_group>/<variable_node_id>
- /
<path_to_dataset> and <path_to_group> are
respectively a path to a group or dataset in the file. The path can be
absolute (starting with “/”) or a relative (not starting with “/”). A
relative path references a node that is a child of the group containing
the references specification.
The first form (a) specifies a reference to a particular dimension of a dataset. In this case all values in the referencing dataset should be integers that are equal to one of the indices in the referenced dataset dimension. Zero-based indexing in used.
The second form (b) specifies a reference to a particular component of a structured dimension. Structured dimensions are described in the Section 2.4.2 dimension specification. In this case each value in the referencing dataset should be equal to a value in the referenced component of the referenced dataset and the values of the component in the referenced dataset should all be unique. This case corresponds to foreign key references in relational databases with the referenced component being a column in the referenced table satisfying a uniqueness constraint.
The third form (c) allows referencing variable-named groups or datasets. In this case all values of the referencing dataset should be names of groups or datasets that are created with the name specified in the call to the API. The value of the reference target specification should contain the name of the group or dataset in angle brackets (since the name is variable) and have a trailing slash if it is a group (since groups are designated by a slash after the name).
The forth form (d) is a single slash. This form is to indicate that the values in the referencing dataset must link to a group or dataset somewhere in the file, but there are no other constraints.
2.4.1.6. Dataset “link”¶
The link specification is used to indicate that the dataset must be implemented using a HDF5 link. Either hard or soft links can be used, but soft links are recommended because they indicate the source and target of the link). The link specification is a Python dictionary. It has the following form:
{
"target_type": "<target_type>"
}
<target_type> specifies the identifier for a dataset in the top level
structure of a namespace. It is used to indicate that the link must be
to an instance of that structure. If “target_type” is not specified, then
the link can be to any dataset id.
2.4.2. dimension specification¶
Within a dataset specification, there are two types of dimension specifications. The first, described in Section 2.4.1.3 Dataset dimensions, provides a list of the names of all dimensions in the dataset. The second (described in this section) provides a way to describe the properties of each dimension. It is not necessary to include the specification for all dimensions. Only those dimensions that have structured components (which are described here) need to be specified. These dimension specifications have a key equal to the name of the dimension, and the value is the specification of the properties of the dimension. The following format is used:
{
"type": "structure",
"components": [
{ "alias": "var1",
"unit": "<unit>",
"references": "<reference target specification>"},
{ "alias": "var2", ... }, ... ]
}
The “type” specifies the type of dimension. Currently there is only one type implemented, named “structure”. Type “structure” allows storing different types of data into a single array similar to columns in a spreadsheet or fields in a relational data base table.
The different components are specified using a list of dictionaries, (or
a list of lists of dictionaries if there are more than one possible
structure; see below) with each dictionary specifying the properties
of the corresponding component. The “alias” specifies the component name that
can be referenced in a <reference target specification>
(reference type “b” in Section 2.4.1.5 “references”).
“unit” allows specifying the unit of measure for numeric values. “references” allows specifying that the values in the component reference another part of the file using any of the methods described in Section 2.4.1.5 “references”.
The list of components can be a list of lists, which allows specifying more than one possible structure for the dimension. An example in which this is useful is for representing a field of view, which could be 2-D (with components “width” and “height”) or 3-D (with components: “width”, “height” and “depth”). The same functionality might be achieved by defining two structured (“fov2d”, “fov3d”) and including both in the list of dimensions. In either case, determining which dimension (or list of dimension components) matches the dataset stored in a file requires matches the number of components in the structured dimension specification to the number of components in the data.
2.5. Autogen¶
2.5.1. Purpose and overall form¶
The autogen specification is used to specify that the attribute or dataset contents (values) can be derived from the contents of the HDF55 file and automatically filled in by the API. An API may use the autogen specification to automatically generate the values when creating a file, and to ensure that correct values are stored when validating a file. (In this section, the values specified by the autogen will be denoted by the phrase “value of the autogen” or “autogen contents.”) The autogen specification has the following form:
{
"type": <type of autogen>
"target": <path_to_target>,
"trim": <True or False; default False>
"allow_others": <True or False; default False>
"qty": <Either ‘!’ – exactly one, or “*” – zero or more; default “*”>
"tsig": <target_signature>
"include_empty": <True or False; default False>,
"sort": <True or False; default True>,
"format’: <link_path_format>
}
<Type of autogen> is one of:
"links", "link_path", "names", "values", "length", "missing"
The <Type of autogen> is the type of autogen. They are described in the
sections below. For all types, except “missing” key “target” is required.
All other keys are optional.
<path_to_target> is a path of identifiers that specifies
one or more groups or datasets that are descendant of the group that most
directly contains the autogen specification. To specify multiple
members the target path would have one or more variable-named id’s
(enclosed in <>). In addition, the target “<*>” indicates
any group or dataset.
If “include_empty” is True, then if no values are found that would be used to fill the autogen, the value is set to an empty list. Otherwise, the container for the autogen values (attribute or dataset) is not created.
The “tsig” value (<target_signature>) is used to specify properties that
must be satisfied for matching target(s). It is used to filter the nodes (groups
or datasets) found at the target path to only those for which the autogen
should apply. <target_signature> has the following form:
{ "type": <"group" or "dataset">,
"attrs": { "key1": <value1>, "key2": <value2>, ... },
}
At least one of the keys (“type” or “attrs”) is required and both may be present. The value for “type” specifies the type of the target node (either “group” or “dataset”). If not included, both groups and datasets match. “attrs” specifies the attribute keys and values that are compared to those in the target to detect a match.
2.5.2. autogen type “links”¶
<type of autogen> value “links” indicates that the value of the autogen
is a list of paths that link to the group or dataset specified by the <target_signature>.
If “trim” is True then when the paths are stored, if they all share the same trailing
component (e.g. /foo/bar/baz, and /x/y/baz; both share final component “baz”),
then the common final component is trimmed from the paths before using them
to fill in the data. If “sort” is true, values must be sorted.
2.5.3. autogen type “link_path”¶
<type of autogen> value “link_path” indicates that the value of the autogen is the
path of a link made from the referenced group or dataset. For example, if there is
a group “foo” which is links to group “bar”, and a dataset named “baz” at the same
level, defined by:
"baz": {"autogen": {"type": "link_path", "target": "foo"}}
Then the value of “baz” should be the path to “bar”.
The “format” option allows specifying a formatting string used for
“link_path”. It can include strings: “$s” to indicate the source of a
link and “$t” to indicate the target. If present, the format is used to
create the “link_path” entries. Default format is: “$t” (include just
the target path). Another common format is "'$s' is '$t'" which will
generate strings like: '<source>' is '<target>' The ‘qty’ for
“link_path” is currently not used. If “trim” is True both the “prefix”
and “suffix” of any matching paths are trimmed. The “prefix” is defined
as the path to the group that most directly contains the autogen
specification. The “suffix” is defined as any components of the matching path
which are to the right of the rightmost component associated with a
“variable named” node (that is, identifier enclosed in “<>”). If there
is no path component associated with a variable named node, the suffix
is not trimmed.
2.5.4. autogen type “names”¶
<type of autogen> value “names” specifies that the value of the autogen
is an array contining the names of groups and/or datasets referenced by
the <target_signature>. If “sort” is True, the values must be sorted.
2.5.5. autogen type “values”¶
<type of autogen> set to “values” specifies that the the autogen contents
is an array listing all values stored in the target data set(s) as a set (no
duplicates). If “sort” is True, the array is sorted. The values in each target
data set must be an array of strings.
2.5.6. autogen type “length”¶
<type of autogen> value “length” specifies that the value of the autogen is the
length of the target which must be a dataset storing a 1-D array.
2.5.7. autogen type “missing”¶
<type of autogen> value “missing” specifies that autogen contents
is a sorted list of all members within the group which are specified as
being required or recommended, but are missing. There is no target
specified. If “allow_others” is True, then the list can also include
additional identifiers, as long as they are not present in the group,
whether or not they are defined in the specification as being required
or recommended. If present, such additional identifiers should be indicated
with a warning during validation.
2.6. Relationships¶
Relationships are specified in one of two ways:
- By sharing a common dimension identifier. Two arrays that are in the same group and which have a common dimension identifier are related to each other through the common dimension. Specifically, for a given index value “i” into the common dimension, the value in the two arrays at that index are related. For example, if arrays “data” and “timestamps” have a common dimension named “num_times”, then the values in these arrays that share the same index for “num_times” will be related.
- Through references specifications in dataset specifications that are described in Section 2.4.1.5 “references”.
2.7. Default custom location¶
An optional dataset named “__custom” (two leading underscores) is used as a flag in the format specification to indicate the location within which custom groups and custom datasets are created by default (that if, if the path is not specified in the API call).